We Finetuned Qwen 3 32B to Replace an LLM API. The Evaluation Was Harder Than the Training.
How to evaluate a finetuned LLM for structured extraction when standard metrics don’t work.
Jordan Browne-Moore · May 2026
~15,000 curated training examples · Multi-field financial metric extraction · Qwen 3 32B + LoRA · Precision: upper 90s · Recall: lower 90s
The Task That Doesn’t Fit in a Benchmark
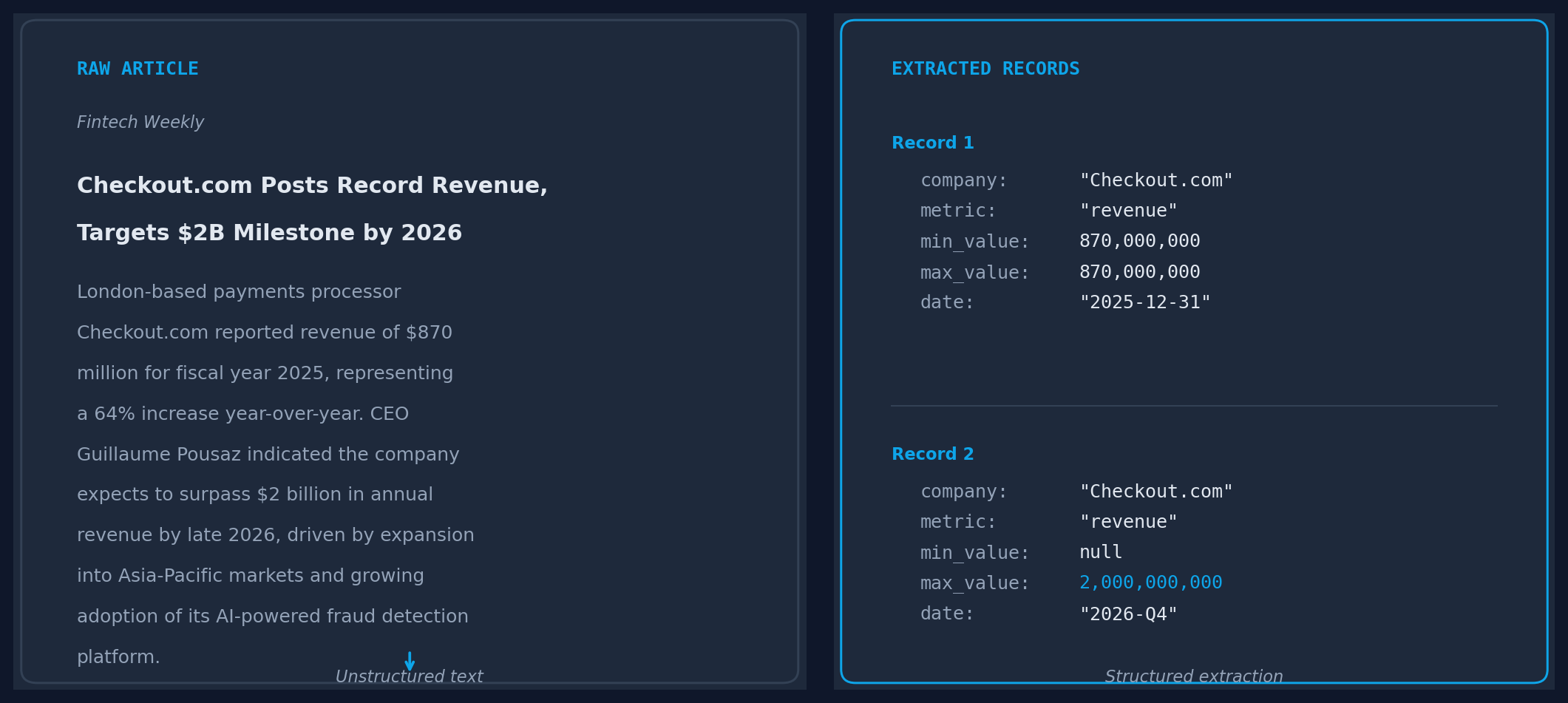
At CB Insights, we needed to extract financial metrics from public signals about private companies. For each mention, the extraction schema required the company name, metric type (revenue, ARR, valuation, funding amount), minimum and maximum values, and the date of the event, across past, present, and future timeframes. A sentence like “the company expects to cross $100M ARR by Q3” contains a projected metric, a value range, and a temporal context that the pipeline needs to decompose into separate structured fields.
The initial approach ran Claude via the Anthropic API for each extraction. It worked. It was also the source of our training data: the production API’s outputs, after hand curation and correction, became the dataset we finetuned on. Cost scaled linearly with volume, and at the throughput we were processing, API spend had become the primary cost driver for the extraction pipeline.
We finetuned Qwen 3 32B with LoRA on approximately 15,000 curated examples and deployed it behind a FastAPI inference endpoint. The training converged without surprises. The evaluation was a different story.
This article is about the evaluation, because that’s where most of the engineering effort went, and it’s the part nobody writes about. The finetuning tutorials are plentiful. What’s missing is a detailed account of how you determine whether a finetuned model is good enough to ship when the task is structured extraction, not chatbot conversation. In our case, the finetuned model didn’t just match the API. It was technically and mathematically more correct. But we only discovered that because we built the right evaluation harness first.
Why Off the Shelf Evaluation Fails Here
Standard LLM evaluation treats output as text a human reads. For structured extraction, that entire approach is wrong. Exact match punishes formatting variance that doesn’t matter (“$45.2M” vs “$45M”). ROUGE rewards well written prose that misses the schema. LLM as judge trades one model’s failure modes for another’s, which is reasonable for open ended generation but circular when you’re evaluating numeric precision in structured output.
The deeper problem is that financial metric extraction isn’t classification. A single article might contain multiple metrics across different timeframes, each requiring separate extraction. It’s a many to many problem, and the evaluation needs to handle that.
What you actually need to measure, independently:
- Does the model produce output that conforms to the expected structure?
- How do you match extracted records to expected records when the same data can be expressed differently?
- What are precision and recall once matching is established?
- Where exactly do the models disagree, element by element, and which one is right?
Format Adherence: Why We Went 32B
We initially tried a 14B parameter model. The 14B model could extract the right information but couldn’t reliably produce it in the complex JSON structure the pipeline required: missing fields, incorrect nesting, type errors. The model understood the content but couldn’t maintain structural consistency across a longer output sequence.
Moving to Qwen 3 32B solved this. Format adherence reached 99.9 to 100%. This contradicts the common advice that 7B to 14B models are sufficient for structured extraction. That’s true for simple schemas. If you need {company: str, revenue: int}, 14B handles it. Our schema encoded temporal context, currency normalization, metric type distinctions, and multilevel nesting. For that level of domain complexity, 32B was the minimum that achieved production grade format adherence, and I’d skip the 14B iteration for complex schemas next time.
We had lightweight postprocessing in the pipeline that could fix minor format issues: normalizing currency strings, repairing truncated JSON, filling default values for optional fields. But healing masks problems. Format adherence at the model level prevents them, and it’s cheaper.
The Matching Problem
Once the output parses correctly, you need to determine whether the extracted content is right. For financial extraction, “right” isn’t binary.
A single article might mention three revenue figures: FY2023 actual, FY2024 guidance, FY2025 projection. The model needs to extract each as a separate structured record with the correct temporal context. The evaluation needs to match extracted records against expected records without assuming a 1:1 correspondence.
We treated this as a bipartite matching problem. For each article, the harness computed pairwise semantic similarity between every extracted record and every reference record. We then ran Hungarian algorithm assignment to find the optimal one to one matching that maximized total similarity, with a minimum similarity threshold below which a pair was rejected as unmatched. Extracted records with no match above the threshold counted as false positives. Reference records with no match counted as false negatives. near duplicate extractions (where the model extracted the same metric twice with minor variation) were deduplicated before matching using field level overlap rules.
Semantic similarity served as the matching mechanism, not as an evaluation metric. It answered “which extraction corresponds to which ground truth entry?” Once that alignment was established, we calculated precision and recall against the matched pairs.
Interextraction Differences: The Diagnostic That Changed the Story
Precision and recall tell you the aggregate picture. They don’t tell you where the models disagree or why.
For every article, we compared the finetuned model’s extractions against the reference model’s extractions element by element. We did not just compare record counts. For each matched record we asked: did they choose the same metric type? The same date? The same value range?
Every disagreement was logged at the element level across the entire evaluation set. “Model A extracted revenue with date 2024-01-15, Model B extracted revenue with date 2024-03-20.” “Model A extracted ARR, Model B extracted total revenue.”
This served two purposes. First, it was diagnostic for model improvement. If the finetuned model consistently chose the wrong metric type on a specific category of article, that pointed to a training data gap. If dates were frequently off by a quarter, that pointed to a temporal parsing issue we could address with targeted data augmentation.
Second, it revealed that the finetuned model was more often correct than the API baseline in cases of disagreement. Manual review of the interextraction differences showed the finetuned model choosing the right metric, the right date, or the right value interpretation at a higher rate than the reference.
The most likely explanation is the hand curated training data. The 15,000 examples weren’t scraped and auto labeled. Each was reviewed for accuracy and consistency. The curation process corrected errors in the reference model’s outputs: misattributed dates, conflated metric types, incorrect value ranges. The finetuned model learned from corrected data, so it reproduced the corrections. Whether the base model’s inductive biases also contributed is harder to disentangle, but the curation as mechanism story is supported by the specific error categories where the finetuned model improved most, which directly corresponded to the error categories most frequently corrected during curation.
And the curation effort, which is unglamorous and easy to under-invest in, turned out to be the single most important decision in the entire pipeline. The gap between 15,000 curated examples and 50,000 auto labeled examples is substantial, and it shows up exactly in these element level disagreements.
What Caught Us Off Guard: Article Length in Production
The biggest production surprise was document length. Development and evaluation used articles within a typical range. In production, we encountered articles significantly longer than anything in the training or evaluation sets.
The model’s extraction quality degraded on longer articles in ways our evaluation didn’t catch, because our evaluation set didn’t contain articles of that length. The model would miss metrics buried in the middle of a long piece or conflate metrics from different sections.
Posthoc context extension via RoPE scaling produced inconsistent results; it works best when trained in from the start. The reliable fix was upstream: chunking long articles before extraction, with overlap to avoid splitting midsentence where a metric might be stated. Not elegant, but production stable. The better fix, training with extended context from the start, is something I’d build into the next iteration.
This is the kind of distribution shift that standard evaluation pipelines don’t catch. No benchmark evaluates extraction quality as a function of document length. If you’re building an evaluation harness for structured extraction, explicitly construct your evaluation set to cover the full distribution of production inputs, including the tail.
The Cost Decision
The cost structure shifted from linear per extraction API pricing to fixed GPU infrastructure. A finetuned Qwen 3 32B served via vLLM on a RunPod instance costs the same whether it processes 10,000 or 100,000 articles. The amortized per extraction cost dropped by approximately 80%.
The quality case was at least as strong as the cost case. The finetuned model matched or exceeded the API on every evaluation metric: format adherence, precision, recall, interextraction accuracy. In cases where the models disagreed, the finetuned model was more often correct. When quality is comparable or better and cost drops by 80%, you don’t need a complex ROI model.
What I’d Do Differently
Define evaluation before training. We built the evaluation harness in parallel with finetuning, which meant we couldn’t use it to guide early training decisions. The interextraction differences turned out to be the most diagnostic metric. If that had been running from day one, we’d have caught the finetuned model outperforming the baseline earlier and made better decisions about when to stop iterating on training data.
Include long documents in the evaluation set. The article length production surprise was avoidable. Construct training and evaluation sets that explicitly cover the tail of your production distribution, not just the typical case.
Start with 32B for complex schemas. The 14B experiment confirmed what the schema complexity should have predicted. For schemas with nested structure, temporal context, and many to many extraction, 32B was the minimum. I’d skip the 14B iteration next time.
If You’re Considering This Path
Finetuning to replace an LLM API makes sense when the task is narrow and structured, you have thousands of hand curated training examples, you can define “good enough” before you start training, and your volume makes fixed GPU infrastructure cheaper than per token API pricing.
It doesn’t make sense when the task requires broad general knowledge, you’re iterating rapidly on the task definition, your volume is low enough that API costs aren’t material, or you don’t have a labeled evaluation set that represents production data including edge cases.
The part most teams get wrong isn’t the finetuning. It’s the evaluation. If you can’t measure whether the finetuned model is good enough, you can’t make the cost quality tradeoff decision. The evaluation harness, semantic matching for record alignment, element level difference tracking, and production distribution coverage, is the engineering investment that makes everything else possible.
If you’re evaluating this tradeoff for your own pipeline, I’m happy to talk through it.
Source code for the evaluation harness and training pipeline is available on request.
← Back to home