Your LLM Extraction Pipeline Is Out of MRM Scope. Your Credit Model Isn’t. Now What?
SR 26-2 carved GenAI out of MRM scope. But when LLM-extracted features feed a credit model, the validation boundary runs through your data pipeline. Here’s how to govern the seam.
Jordan Browne-Moore · May 2026
SR 26-2 · SS1/23 · DORA · AI Act · Two-stage pipeline governance · Extraction evaluation harness
Every analysis of SR 26-2 says the same thing: GenAI is carved out of MRM scope, but it’s not a green light and governance still applies. I’m not going to rehash that. What nobody is explaining is the practical problem the carve-out creates for teams that actually build LLM pipelines in financial services.
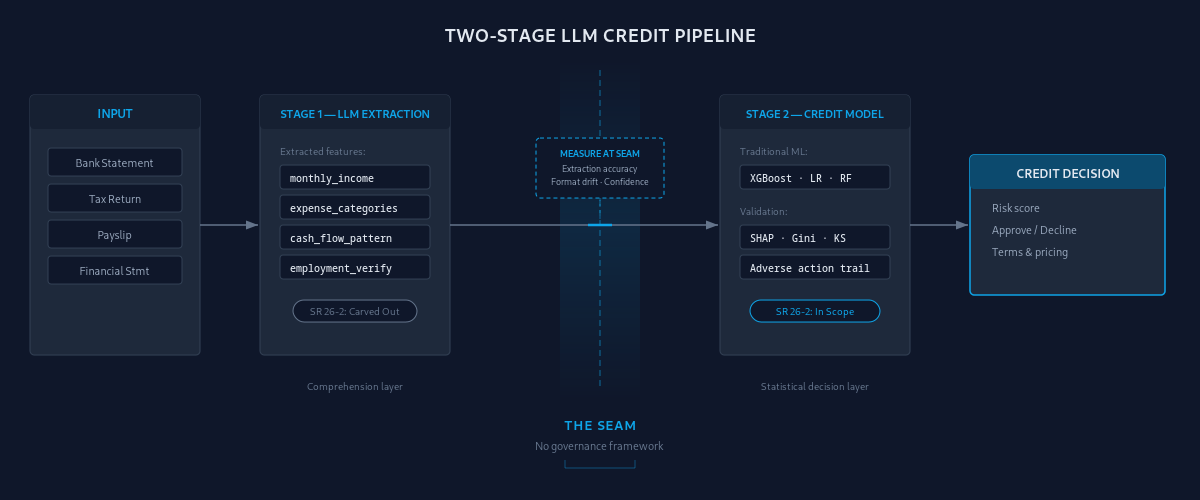
The production architecture I’ve built and that I see across the industry looks like this: an LLM extracts structured features from bank statement PDFs. Those features feed a gradient-boosted credit scoring model. The scoring model is unambiguously in MRM scope under SR 26-2. The LLM extraction pipeline is unambiguously carved out. The integration point between them, where unstructured text becomes a model input that influences a credit decision, has no framework at all.
That’s not a policy debate. That’s a Tuesday morning architecture decision that determines whether your pipeline survives regulatory scrutiny. I’ve built both sides of this, credit models in regulated environments and LLM extraction pipelines in production, and the boundary question isn’t theoretical for me. Here’s how I think about it.
The Architecture Everyone Is Building
The dominant production architecture for LLMs in credit is not “LLM makes credit decisions.” Nobody serious is doing that. The real pattern is a two-stage pipeline.
Stage 1 is LLM extraction. Unstructured documents go in: bank statements, tax returns, payslips, financial statements. Structured features come out: monthly income, expense categories, cash flow patterns, employment verification signals. The LLM’s job is comprehension. “What is the average monthly deposit over the last six months?” is a reading question, not a credit question.
Stage 2 is a traditional scoring model. Structured features, including LLM-extracted ones, go in. A credit decision or risk score comes out. Logistic regression, XGBoost, random forest. Explainable. SHAP values. Clean adverse action trail. Everything a regulator expects.
The LLM handles format variation across document types and issuers without requiring new extraction rules for every bank’s statement layout. The credit model handles the statistical relationship between features and default probability. Neither can do the other’s job well.
I’ve seen this pattern in production: LLM-extracted cash flow features materially improve discrimination for thin-file segments where bureau data is sparse. Academic work is beginning to confirm what production teams already know. Xia et al. (2025) applied this two-stage pattern to P2P loan narratives in the International Journal of Forecasting with comparable results, though the extraction challenge differs: P2P narratives are already text, while bank statements are semi-structured documents where layout comprehension matters as much as language comprehension.
Under SR 26-2, Stage 2 is fully in scope. Stage 1 is carved out. The connection between them is where the governance ambiguity lives.
The Model Boundary Runs Through Your Data Pipeline
Here’s the problem in concrete terms.
When the credit model’s validation documentation says “Input: monthly_income,” the validator needs to know where that number came from. If it came from a structured API call to a payroll system, the provenance is clean. The data source is documented, the feed is deterministic, the number means what it says.
If it came from an LLM reading a bank statement PDF, the provenance chain now includes document quality (scan resolution, image clarity, whether the PDF is native text or a photograph), extraction accuracy (did the LLM read the right number from the right row?), format normalization (is “$4,523.67” being parsed the same way as “4523.67” or “4,523.67 CR”?), and temporal alignment (is this the reporting period the model expects, or did the LLM pull a year-to-date figure instead of a monthly one?).
Each of those is a failure mode that can produce a wrong credit decision. The credit model might be perfectly validated against its inputs, but its outputs are only as good as what goes in.
The credit model is in scope. Its inputs are part of its validation. The LLM produced those inputs. So the LLM’s output quality is functionally part of the credit model’s validation even though the LLM itself is carved out of MRM scope. The interagency guidance makes this clear: traditional statistical and quantitative models remain fully within scope, and when a GenAI system feeds a traditional model, the traditional model doesn’t get a pass on validation just because one of its inputs comes from carved-out technology. The aggregate integration is part of the model’s risk surface.
I know exactly how this plays out because I’ve lived it. At an institution where I built this architecture, we had an extraction evaluation harness running, but it was silently breaking. The golden dataset it validated against hadn’t been refreshed when we onboarded new bank statement formats. The harness kept passing because it was testing the LLM on old formats it already handled well. Meanwhile, extraction accuracy on monthly income for the new formats had degraded significantly. The credit model’s discrimination metrics barely moved because the degradation was concentrated in a thin-file segment too small to shift portfolio-level Gini. But for the affected borrowers, the model was systematically underestimating income and producing worse terms. We only caught it when a quarterly fair lending review flagged a spike in adverse actions tied to a single new issuer. The model monitoring hadn’t caught it because the model was performing as designed on its inputs. The harness hadn’t caught it because the harness wasn’t testing the right documents.
This means three decisions land on your desk, and the guidance doesn’t make them for you.
Where do you draw the validation boundary? There are three postures I’ve seen teams adopt, and the difference between them is which failure modes at the seam you’re willing to accept as unmonitored residual risk.
Posture 1: treat LLM outputs as data. Validate the credit model only. Extraction quality is engineering’s problem. This is the cheapest option and the one most likely to produce an adverse examination finding, because if the model’s inputs are wrong and you didn’t monitor the input source, the model validation is incomplete regardless of what the guidance says about the input source’s regulatory classification.
Posture 2: validate the credit model with extraction-quality monitoring as a supplementary control. The extraction pipeline isn’t formally “in MRM scope,” but you build monitoring at the seam, extraction accuracy, drift, format adherence, and reference it in the credit model’s validation documentation as input quality assurance. This is the pragmatic middle ground and probably where most institutions will land.
Posture 3: validate the full pipeline end-to-end. Treat the LLM extraction as part of the model boundary for validation purposes. Most rigorous, highest overhead, hardest to execute technically because the LLM is non-deterministic and traditional backtesting doesn’t directly apply.
What do you measure at the seam? Extraction accuracy per field. Format adherence rate. Confidence score distribution. Drift in extraction quality over time. These are pipeline metrics, not credit model metrics. But they determine credit model performance, which means they belong in the validation documentation.
Who owns the boundary? Model risk owns the credit model. Engineering owns the extraction pipeline. The integration point sits in organizational no-man’s land unless you explicitly assign it.
What the Proactive Banks Are Doing
The industry is split, and the split is instructive.
Some GSIBs were already validating GenAI under SR 11-7 before it was withdrawn (Risk.net, May 2026). Citi’s Krishan Kumar Sharma, SVP in model risk management, published a six-pillar GenAI governance framework in the Journal of Operational Risk (March 2026). His core recommendation: formally classify GenAI systems as models within MRM regardless of the carve-out, mandate human-in-the-loop review as the primary control for hallucination risk, and maintain auditable prompt libraries. His argument, also reported by Risk.net: validation identifies the risks and weaknesses of GenAI systems, which supports the rest of the model risk management framework even when the regulation doesn’t require it.
The counterargument is real. An AI head at a large global bank told Risk.net: “I don’t think Copilot should be validated. You cannot validate a foundation model.” The non-deterministic outputs make traditional backtesting and outcome analysis difficult or impossible. This is a legitimate technical objection, not laziness.
But here’s the resolution, and it applies directly to the boundary problem: you don’t validate the foundation model. You validate the pipeline. Extraction accuracy on your specific documents. Format adherence on your specific schema. Consistency across your document formats. Drift over your production timeframe. These are measurable, testable, and auditable. The foundation model is a black box. The pipeline’s outputs are observable. You can test extraction accuracy, consistency, and drift without explaining the LLM’s internal reasoning, but you must document that explainability gap as a known limitation. That’s enough for validation, provided you’re honest about what you can’t explain.
The pattern here is the same one that produced SR 11-7 in the first place. Regulators let industry practice mature, then codified it. The banks building governance now are writing the future guidance.
The Transatlantic Problem
If you’re building LLM pipelines for a firm that operates across jurisdictions, the boundary decision gets harder because the regulatory answer differs depending on where you sit.
In the US post SR 26-2, GenAI is carved out of MRM scope. The boundary is yours to define. The RFI is coming. In the interim, governance falls to fair lending law, FCRA, NYDFS Part 500, state AI laws, and whatever internal framework you build.
In the UK, SS1/23 still applies and has never carved out GenAI. The PRA issued minor clarifying amendments in April 2026 (via LIAF01/26), but the core framework is unchanged: the entire pipeline, extraction and scoring, falls under model risk management principles if it influences a regulated decision. Explainability, fairness, and accountability requirements apply to the LLM extraction layer, not just the credit model.
In the EU, DORA applies from January 2025 with ICT risk management and third-party oversight requirements. The AI Act’s high-risk system requirements are currently set for August 2, 2026, with credit scoring explicitly listed as high-risk, though trilogue negotiations on the Digital Omnibus proposal may push this to late 2027. Either way, the framework adds conformity assessment and transparency obligations that are structurally different from anything in SS1/23 or SR 26-2.
These jurisdictions are converging on one principle — the extraction layer influences a regulated credit decision so it needs governance — but diverging on the mechanics. There is no single “strictest regime” you can build for and automatically satisfy the others. The PRA expects MRM principles applied across the pipeline. DORA adds ICT risk and third-party oversight that MRM doesn’t cover. The AI Act adds conformity assessment and documentation requirements that neither SS1/23 nor SR 26-2 address.
A Governance Framework for the Seam
Here’s what I build at the integration point between the LLM extraction pipeline and the credit model. Four components.
Extraction evaluation harness. Before the LLM pipeline goes into production, and continuously after: measure extraction accuracy per field, format adherence rate, confidence score distribution, and failure mode frequency. I evaluate against a golden dataset of human-annotated documents, refreshed quarterly and updated whenever new document formats enter the portfolio, measuring field-level accuracy and format-specific performance across document issuers. The harness runs on every model version change and on a rolling sample of production documents. This is the equivalent of backtesting for the extraction layer.
If extraction quality degrades, the credit model’s inputs degrade, and no downstream monitoring catches it. Crucially, I test specifically for fabrication. Hallucination is the failure mode every VP of Risk asks about first: what happens when the LLM just makes up an income number? The confidence score distribution must flag not only low-confidence extractions, but also false certainty — high confidence on a fabricated or misattributed value. I cross-check high-confidence extractions against arithmetic consistency: does the sum of monthly deposits match the stated total, does the extracted income fall within the historical range for this issuer’s format. That catches cases where the LLM is confidently wrong, which is the harder problem and the one you must design for explicitly.
I’ve open-sourced a feature stability toolkit that handles one layer of this problem: it treats feature stability as a learning curve, varying pool size across bootstrap resamples to separate structural instability (won’t resolve with more data) from volume instability (will). The “floor” parameter it fits tells you whether a feature’s behavior is fundamentally unstable or just sample-dependent. For LLM-extracted features, a high floor on an extraction that looked clean in development is exactly the signal that something at the seam isn’t generalizing. The production evaluation harness extends beyond this to continuous monitoring and format-specific accuracy tracking across the boundary.
Input provenance documentation. Every feature in the credit model’s input vector needs a documented source. For LLM-extracted features: each is logged with document hash, extraction prompt version, model version, confidence score, extraction timestamp, and the source document page or region so a reviewer can verify the extraction against the raw document. This is queryable by the validation team and included in the credit model’s input documentation by reference. It’s what the validator needs to assess the credit model end-to-end, and it’s what a well-constructed RFI response would demonstrate as standard practice.
Drift monitoring across the boundary. Document format distributions change. Banks update statement layouts. New issuers appear with formats the LLM hasn’t seen. I track the distribution of extracted features by document issuer and format version. A shift in extracted income distribution that correlates with a new issuer entering the portfolio triggers an extraction accuracy review before it triggers a model performance review. The LLM is failing on a new format. The borrowers’ incomes haven’t changed.
Organizational ownership map. Who owns the extraction pipeline? Who owns the credit model? Who owns the seam? If model risk validates the credit model but engineering owns the extraction, there’s a governance gap at the integration point. Define it. Document it. Make sure both sides monitor for the same failure modes and escalate on the same triggers.
If you’re preparing an RFI response, this is what I’d document: a governance framework that extends from the unstructured document through the LLM extraction through the model boundary to the credit decision, with measurement at every transition. Not theoretical. Not a policy position. Working infrastructure that produces auditable evidence as a byproduct of normal operations.
The Boundary Is the Architecture
SR 26-2 carved GenAI out of MRM scope. The RFI will eventually fill the gap. In the meantime, the architecture doesn’t wait for the regulators.
Your LLM extraction pipeline is producing features that feed a credit model that makes decisions about people’s access to money. The governance question isn’t whether the LLM is “in scope.” It’s whether you can demonstrate, to a validator, to an examiner, to a judge, that the full pipeline from unstructured document to credit decision is measured, monitored, and controlled.
The feature stability toolkit referenced in the governance framework is open-sourced at github.com/ElSnacko/feature-bootstrapping-toolkit.
← Back to home