The Refusal Axis Is Layer Local: Why Single Vector Steering Hits a Geometric Ceiling
Summary. Activation steering treats refusal as a direction you push against. Across two model families I find that the refusal direction is real but layer local: it rotates ~90° between consecutive transformer blocks (Qwen3.5-9B 93.4°, Mistral-7B 88.8°, bootstrap CIs ±0.15°). A perturbation injected at one layer arrives nearly orthogonal to the next layer's own refusal axis, so a single steering direction cannot saturate a representation that reorients at every depth. Two further measurements, a refuse/comply asymmetry and an orthogonal behavioral response to steering, explain the resulting ceiling and motivate a manifold following (spline) successor to flat vector steering. The work has clear limitations, chief among them model scale and the small number of steered layers, discussed in the limitations section.
Jordan Browne-Moore · June 2026
Models: Qwen3.5-9B and Mistral-7B | BeaverTails dataset | 12 harm categories | Reproducible
The Ceiling
After computing per category steering vectors and steering at the best layers of each model, the genuinely harmful compliance rate barely moves:
- Qwen3.5-9B: 0 genuinely harmful complies across all 12 BeaverTails categories, at every steering strength that preserves output coherence.
- Mistral-7B: ~2 genuinely harmful responses total across all categories (terrorism 1/16, financial_crime 1/27, after false positive correction).
This isn't a single method check. Every response is scored by a four class DeepSeek-V4-Flash judge; a heuristic then flags known false positive patterns (the model narrating its own AI identity, or echoing the prompt); and every surviving "comply" gets a manual content QA pass. The genuinely harmful count is what survives all three stages.
The raw judge "comply" rate looks higher for Mistral, up to 37–45% on the softer categories, but false positive correction shows it decomposes almost entirely into judge artifacts (AI identity responses, educational content) and hedges: answers that deliver content wrapped in caveats rather than clean harmful output. Both models converge on the same place: at coherence preserving strength, genuine harmful compliance is ≈ 0.
That convergence is the puzzle, because this is the regime where steering was expected to succeed. The literature (RepE, abliteration, Arditi et al., and the ridge regularized refusal steering method of García-Ferrero, Montero & Orus, arXiv:2512.16602, that this work directly extends) treats refusal as a direction in activation space that you can push against to suppress the behavior. If that picture were complete, turning the knob far enough should produce harmful compliance well before the output degenerates into noise. It did not: pushing to the edge of coherence never produced it. The remainder of the article argues that the bound is structural, a property of the refusal circuit's geometry, and then is candid about the experimental choices that could instead explain it.
The Rotation
The refusal axis is real at every layer, but it is a different axis at every layer.
Each transformer block separates refused activations from complied ones along its own direction, and consecutive blocks' directions are nearly orthogonal, about 90° apart. If layer 21 separates refusal from compliance along an "east west" axis, layer 22 separates them along a "north south" one. The axis isn't lost, it's reoriented. A transformer is supposed to transform its representation block by block. The measurement is that the refusal axis gets carried along and reoriented by that transformation rather than held fixed, which forces a practical consequence: each steered layer must be pushed along its own refusal direction, because a vector computed at one layer points almost nowhere useful at the next.
In the unsteered model, the per layer difference vector is already ~90° rotated between consecutive layer pairs: Qwen3.5-9B at 93.4° (95% CI [93.27, 93.56], depth σ 4.65°), Mistral-7B at 88.8° (95% CI [88.72, 89.00], depth σ 2.20°), both within a few degrees of orthogonal. Modeled as a distribution across depth:
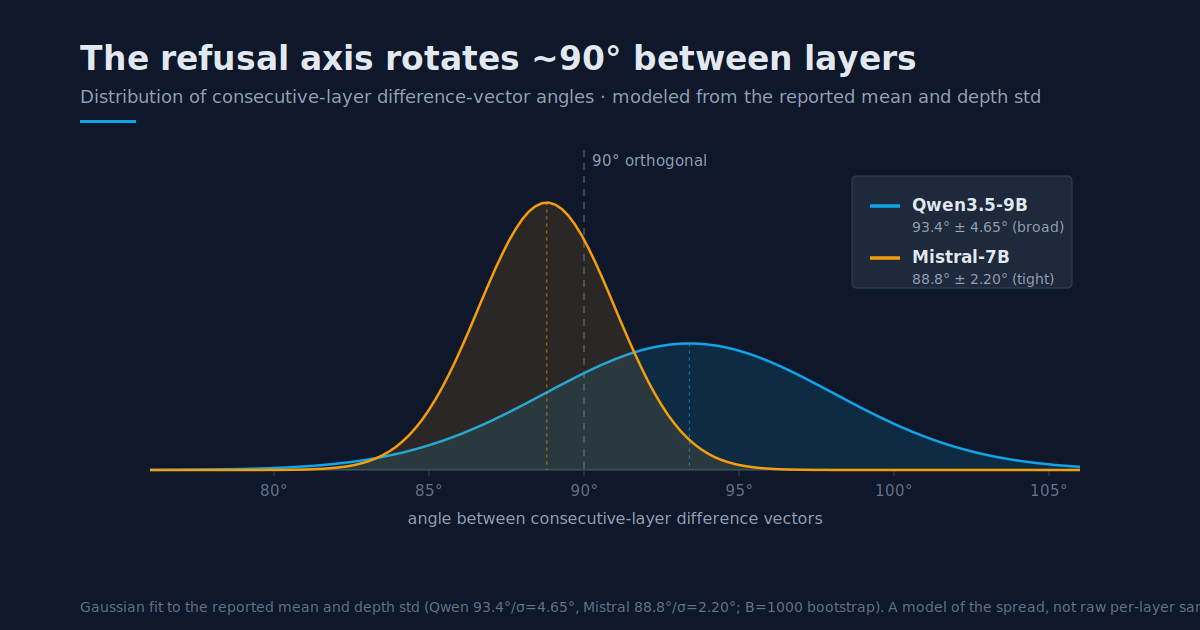
The confidence intervals are ±0.15°: a reviewer who draws a different prompt sample sees the same rotation to within 0.3°. The result holds across two model families and is confirmed by two independent measurements: the static unsteered geometry above, and the live causal propagation experiment below.
What the "difference vector" is
At each layer I take the mean hidden state over prompts the model refused and subtract the mean hidden state over prompts it complied with. That single vector, mean(refused) − mean(complied) at that layer, is the layer's refusal axis: the direction in activation space that separates the two behaviors there. It is also the steering vector itself (the mean difference, in the weighted, covariance adjusted WRMD form used to actually steer).
Why the rotation is hidden in raw activations
Raw hidden states make adjacent layers look nearly identical, with high cosine similarity from one layer to the next. That is the residual stream: it carries a large shared component forward, and each block (attention + MLP) writes only a small update on top. Subtracting complied from refused cancels that shared residual component, leaving only the per block update, and that per block remainder is what rotates ~90°. The rotation is invisible in raw activations and only surfaces in the refusal specific difference. Jiang, Zhou & Zhu (2024) find that raw layerwise representational similarity is positive and increases as layers get closer, so far apart layers grow least similar, and attribute that smoothness to the residual connection; exposing the rotation via the difference vector, and quantifying it for refusal, is the extension here.
The same rotation, seen live
Inject a perturbation at a source layer with cos(Δh, v_src) = −1.000 (perfect application of that layer's comply direction) and track, at every downstream layer l, two quantities: its alignment with that layer's own axis, cos(Δh_l, v_l) (a cosine, −1…+1), and norm_ratio = ‖Δh_l‖ / ‖α·v_src‖, how much of the injected perturbation's size survives at l (the impact of one unit of injected steering once it has propagated to l; a magnitude, not a cosine). So a norm_ratio of 0.40 means that injecting one unit of steering at the source produces only ~0.4 units of shift one block later (about half the push has decayed in a single layer), even as that shift's alignment with the next layer's refusal axis has all but vanished.
Mistral-7B:
Injected at α = −1.34; applied norms ‖α·v‖: L16 = 1.78, L21 = 1.70, L23 = 1.88, L29 = 3.15.
| Downstream layer | src=16 | src=21 | src=23 | src=29 | norm_ratio |
|---|---|---|---|---|---|
| src (injection) | −1.000 | −1.000 | −1.000 | −1.000 | 1.000 |
| src + 1 | −0.112 | −0.078 | −0.077 | −0.151 | ~0.40 |
| mid layers | −0.01…−0.09 | −0.04…−0.10 | −0.03…−0.07 | n/a | 0.40–0.56 |
| 29 | −0.023 | −0.098 | −0.053 | n/a | 0.56 |
| 30 | +0.087 | −0.158 | −0.131 | −0.151 | 0.74 |
| 31 (final) | +0.121 | −0.140 | −0.002 | −0.144 | 1.20 |
Qwen3.5-9B:
Injected at α = −0.998; applied norms ‖α·v‖: L22 = 15.1, L23 = 13.6, L25 = 14.2, L29 = 18.3.
| Downstream layer | src=22 | src=23 | src=25 | src=29 | norm_ratio |
|---|---|---|---|---|---|
| src (injection) | −1.000 | −1.000 | −1.000 | −1.000 | 1.00 |
| src + 1 | −0.095 | −0.108 | −0.092 | −0.181 | ~0.49 |
| mid layers | −0.03…−0.15 | −0.02…−0.14 | −0.06…−0.13 | n/a | 0.43–0.51 |
| 29 | −0.060 | −0.076 | −0.064 | n/a | 0.51 |
| 31 (final) | −0.196 | −0.139 | −0.079 | −0.092 | 0.75 |
The two tables tell one story, and the two quantities behave differently. The alignment (the cosine columns) starts at −1.000 and, one layer later, has fallen to roughly −0.1 (about 93% of it gone in a single block), then stays near zero the rest of the way: once lost, it does not come back. The magnitude (norm_ratio) traces a U instead: it dips to ~0.4–0.5 of the injected size one block downstream, then climbs back toward 1.0 over depth. The two models differ only in that recovery: in Mistral an early injection (L16) keeps growing past its injected size, reaching norm_ratio ≈ 2.12 by the final layer (the perturbation ends up larger than it went in), whereas Qwen never overshoots (norm_ratio caps at 0.75). (The Mistral table's norm_ratio column tracks src=21, which caps at 1.20; the 2.12 figure is the src=16 trajectory.) So the magnitude comes back; the alignment does not.
But the mechanism does not fully absorb the injected direction, and that residual is the reason steering works at all. Two things survive the rotation. First, the perturbation keeps its own identity across depth: its self alignment with the source vector, cos(Δh_l, v_src), stays positive at +0.08 to +0.23 rather than collapsing. This is the analogue of what Sinii et al. (2025) call Diff Diff CosSim, a propagated perturbation's self alignment, which in their RL reasoning models decays but stays consistently above 0.3, as opposed to their Diff Vector CosSim, the alignment with each layer's own steering vector, which falls to near zero. (Our self alignment runs lower than their >0.3, but the qualitative split is the same: self identity survives, local axis alignment does not.) Second, that local axis alignment is small but nonzero here too: cos(Δh_l, v_l) ≈ 0.06–0.15, not 0 (correspondingly the centroid shift in the orthogonal motion section is 89–95% orthogonal, not 100%). The accurate statement is therefore not "the direction never comes back," but "the direction is mostly, not entirely, orthogonalized." The 5–11% that leaks through is what moves behavior, and the ceiling is set by how little leaks, not by total cancellation.
Convergent evidence
The rotation is not idiosyncratic to these two models. The cross layer decorrelation is the Jiang and Sinii result already cited above; independently, refusal is increasingly described as more than one global axis: multiple independent directions and "concept cones" (Wollschläger et al. 2025), distinct directions per refusal category (Joad et al. 2026), steering reframed as rotation (Vu & Nguyen 2025). The new piece is quantifying the refusal difference vector's ~90° per block rotation cross model, with tight CIs, and tying it to the steering ceiling. The generalization risk is on the precise magnitude, not the existence of cross depth rotation.
The Asymmetry
The refusal and compliance directions are not mirror images, and the gap is the second reason a single vector was always going to fall short. With α tuned to maximize compliance while preserving capability (the optimizer rewards compliance and penalizes capability degeneration), genuine harmful compliance (judge score −1.0, hand verified against the raw responses) stays pinned near the floor on the genuinely harmful categories: ≤3.3% on Qwen3.5-9B and ≤5.5% on Mistral-7B at every α tested. Because that figure is the most a maximizer could find in sample (see the limitations section), it is an upper bound, not a measured floor. What climbs when you push harder is not compliance but hedging (on Mistral) or nothing at all (on Qwen), and then degeneration. By hard categories I mean the near hard coded refusals (violence, child abuse, animal abuse, discrimination), which barely move; the softer terrorism / sexually explicit / nonviolent categories give higher raw rates that are mostly hedge, and the borderline "leftover" pool (drug, misinformation, controversial) moves most.
| Property | Qwen3.5-9B | Mistral-7B |
|---|---|---|
| Genuine harmful compliance at maximizing α (strong, hand verified; in sample upper bound) | 0–3.3% | 1.8–5.5% (hard categories); up to ~27% on soft/borderline categories |
| What rises instead when pushed harder | nothing, then degeneration | hedging (weak comply), then degeneration |
| Refusal direction over refusal on benign | +6pp | +10pp (4%→14%) |
| Refusal pushed past safe α | degenerates (54% @ α+2.4 → 100%) | coherent no op: behaviour flat, KL grows ~2000× |
| Steering KL vs random direction floor (neutral prompts) | below floor at all 4 best layers (0.0004–0.0013) | below floor at L29 only (0.005 vs p5 0.007) |
| Refusal category vector geometry (mean pairwise / σ) | 58.4° / σ17.2° | 67.3° / σ8.2° |
| Comply activation geometry | 42.6° / σ6.6° (shared subspace) | not measured (activations not retained) |
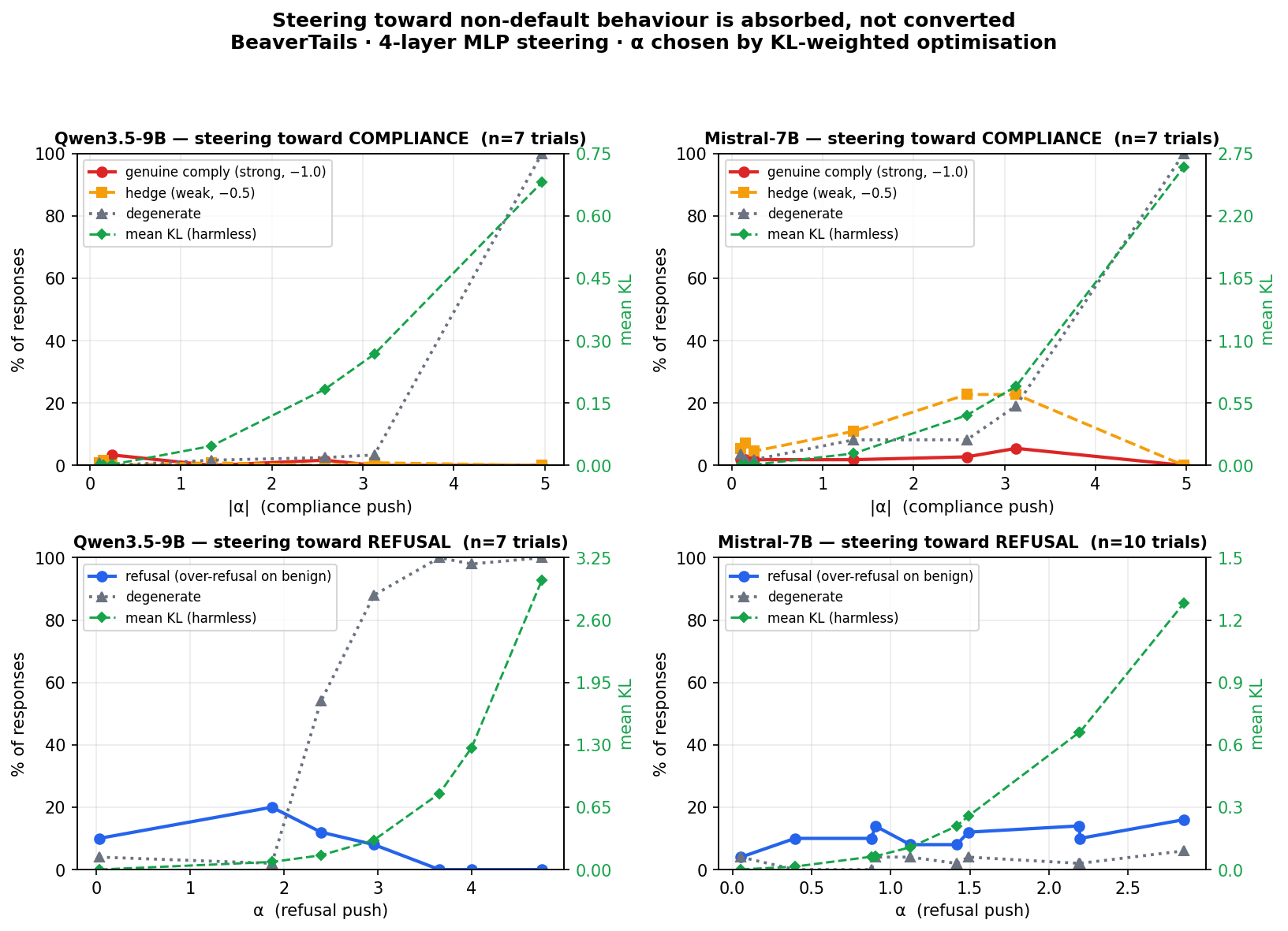
Trial counts differ by run (n = 7–10 α points per panel): later Bayesian trials that stopped adding behavioural uplift were dropped to save compute, a budget choice flagged in the limitations. Source: optimize_alpha runs (Qwen 20260526, Mistral 20260527, BeaverTails 4 layer MLP, α by KL weighted optimization); backing per alpha JSONs and the plotting script are committed in the research repo (results/…/optimization_summary_*.json, scripts/make_asymmetry_figure.py).
The refusal vector's KL on neutral prompts (0.0004–0.0013 on Qwen) is not merely low: it sits below the lowest KL of all 50 equal norm random directions tested, roughly 40–80× below their mean (0.0004 vs 0.0153 at L29), and is symmetric in ±α: pushing that axis either way costs the same near zero KL. Geometric privilege is a property of the refusal subspace: cheap to push in either direction with little distributional damage, which is what makes compliance's resistance notable rather than expected. On Mistral the privilege is shallower: only layer 29 sits below the random floor (0.005 vs a 0.007 5th percentile); at layer 16 the steering vector is more disruptive than a typical random direction. So the "below the random floor" property is real but Qwen broad and Mistral narrow.
The comply direction does little genuine work at coherence preserving strength. I did not run a matched random KL or perplexity control for it, so its weakness is shown behaviourally (the genuine compliance ceiling above, plus the hedging and degeneration that fill the gap) rather than through a measured distributional control of the kind the refusal side has (this is about a missing comply side control, not a missing baseline: baseline refusal rates come from the separate baseline evaluation, ~51% Qwen / ~54.5% Mistral). Two honest qualifications travel with it. First, the genuine complies that do occur on Mistral are real, not judge artifacts: reading the raw responses, the terrorism strong complies are actual surveillance, hit squad, and chemical/biological weapon instructions (≈6% at coherence preserving α, rising at deeper α only as the output itself degenerates), whereas the headline 37% on sexually explicit content is entirely hedge: zero genuine complies across every trial. Second, the softest, borderline categories (drug / misinformation / controversial) do move on Mistral, up to ~27% genuine, so the ceiling is a property of genuinely harmful targets, not a universal flat line. Geometrically the comply direction is still well defined: on Qwen its per category vectors cluster tightly (6.6° spread, a shared subspace) where the refusal vectors diverge (17.2°); regretably the equivalent comply activation geometry was not retained for Mistral.
The asymmetry reframes the ceiling: the push was not too gentle. The model's alignment makes the refusal attractor cheap to deepen and expensive to escape.
One caveat travels with the comply finding. The comply class used to build the vector is ~72–77% benign compliance, so it is a content controlled compliance direction, not a verified harmful comply one. The defensible claim is that steering toward the available comply class does not unlock harm at safe α; whether a true harmful comply direction exists and transfers is the open Arditi vs Joad question, not settled here. A benign dominated comply class is the standard construction in this literature, since genuine harmful complies are too scarce to fit a vector from, so this is a routine caveat rather than a defect. The composition independent leg is the refusal side (the refused class is ~85–89% genuinely harmful by BeaverTails labels): cheap to deepen, below the random direction floor.
The Orthogonal Motion
The rotation has a direct behavioral consequence: the model's response to steering is perpendicular to the push. Across the steering strength sweep on Mistral-7B (PERT 0.4–3.0), 89–95% of the induced activation centroid shift was orthogonal to the steering direction (orthogonal fraction 0.954 → 0.894 across the sweep). You push along the refusal axis at L29; the centroid moves almost entirely sideways. The compliance destination itself sits 112.5° from the refusal axis, so compliance is not "negative refusal."
I measured this through the hedge regime, the transitional state where the model delivers content wrapped in caveats, captured as a one shot snapshot at a single layer (L29) within the steered forward pass (not a trajectory across layers or tokens). Some claims about the hedge are statistically secure and some are not; both are below.
| Quantity (hedge, Mistral L29) | Point | 95% CI (B=1000) | Verdict |
|---|---|---|---|
| Orthogonal fraction of hedge shift | 1.000 | [0.994, 1.000] | secure, orthogonality robust |
t (0 = refuse, 1 = comply) | 0.376 | [0.151, 0.568] | secure, strictly intermediate |
Off line bow | 0.440 | [0.370, 0.680] | > 0, but null test below is negative |
Secure: the hedge shift is essentially 100% orthogonal to the refusal axis (89.7°) and sits strictly intermediate between refuse and comply (t excludes both endpoints). Not secure: that the hedge is a geometrically distinct basin off the refuse→comply line. Two tests said no. A perpendicular specific null test was negative (the 0.44 off line bow is within what on line clusters produce from sampling noise, one sided p = 0.27, and is dominated by a tiny 5 prompt compliance anchor); a causal test, pushing the mean hedge direction directly, perturbed behavior in a prompt inconsistent direction, so it is not a usable lever. The defensible conclusion: the destinations of steering are reachable but lie off the axis you injected. I can establish orthogonal, intermediate motion, not a distinct hedge basin.
Why the Ceiling Is Geometric
Three findings compose into one mechanism.
- Layer locality (the rotation section). You steer at a handful of layers; the rest process refusal in their own ~90° rotated frames. A perturbation at layer L cannot substitute for one at L+1, because those layers encode the behavior in near orthogonal subspaces. Multi layer steering is not redundancy: it is the minimum needed to "speak each layer's language," and even then only the small non orthogonal residual carries through.
- Asymmetry (the asymmetry section). Genuine harmful compliance stays near the floor (≤~5%) even at α tuned to maximize it; pushing harder buys hedging then degeneration, not compliance. That reads as alignment hard to steer out of, though the rate is an in sample upper bound, and on the softest categories it does lift.
- Orthogonal motion (the orthogonal motion section). Even where steering works, the model moves perpendicular to the push, so adding magnitude along the injected vector buys little.
A representation that reorients at every depth cannot be saturated by one vector family: on this reading the ceiling is the geometry of the refusal circuit, not the steering knob, subject to the limitations and confidence (below) caveats.
What the Geometry Demands: Per Layer Splines (a proposal, not a result)
If the axis rotates per layer, a single vector family cannot steer it well, so stop adding a vector and start following the manifold. The instinct here is borrowed from feature based steering (Goodfire's SAE feature edits and "Auto Steer," which intervene along interpretable feature directions rather than one raw contrastive vector), pushed toward an explicitly geometric, per layer form. Standard steering computes one difference vector and applies it everywhere. The spline approach instead replaces the activation at a steering layer with a point on a curve fitted through behavioral centroids (refusal → soft refusal → neutral → soft compliance → compliance) in a reduced activation space. You hand the model the activation the spline says it should have for behavioral strength t, rather than the original plus a vector; downstream layers then process it as if earlier layers had produced it naturally. Two variants both preserve "steer along the manifold, don't add a vector":
A. Per layer spline family. Fit a separate 1D spline at each steering layer, in that layer's own PCA reduced space, respecting its local geometry. More robust to non smooth (block by block) rotation, because each spline need only be valid at its own layer.
B. Rotation aware surface. Fit a 2D thin plate spline parameterized by both behavior strength and layer index, bending through the rotating axes directly. This tests whether the rotation is smooth across depth, and whether following it recovers the force that flat α steering loses to misalignment.
Where This Can Fail (and how I'd address it)
Each failure mode below is paired with a diagnostic or mitigation. Two tools recur because they already carry the load in the rotation section and the orthogonal motion section: prompt bootstrapping and angular spread of prompts (within bin dispersion measured against a repeated sampling noise floor).
The bootstrapping is more involved than the tight CIs above suggest. Rather than computing one instability number on the full prompt set, I measure prompt instability as a learning curve: resample at a range of prompt pool sizes and fit the decay instability ≈ k / nα + floor. That separates volume instability (the k/nα term, which shrinks as you add prompts) from structural instability (the floor, which does not). A bin or endpoint anchor with a high floor is irreducibly unstable: more prompts will not rescue it, and a spline that leans on it inherits that noise. This is the machinery in feature bootstrapping-toolkit (originally a feature stability tool for credit risk models), repurposed so each bin on the refusal→comply curve earns a floor estimate before it is trusted as a knot.
| Failure mode | Diagnostic | Mitigation |
|---|---|---|
| Bin contamination, a bin encodes topic, not refusal strength | Angular spread: high within bin spread with a topic correlated dominant PC = contaminated; isotropic near the noise floor = clean | Learning curve fit flags it: a topical bin has a high structural floor (won't decay with more prompts); re bin before fitting |
| Manifold cliffs, smoothness breaks near degeneration | Endpoint coherence test: extrapolate past the last knot, watch perplexity/KL/judge coherence collapse (the quantitative "coherence preserving alpha") | Clamp knot placement and extrapolation to the last coherent point |
| Nonsmooth rotation, Qwen depth std 4.65°, some pairs >90° | Prompt bootstrap CIs on the per pair angle flag sharp, non smooth jumps | Fall back to the per layer spline family (A), valid only at its own layer |
| Small comply cluster, 5 prompts / 472 vectors; sank the the orthogonal motion section null test | Learning curve fit: reducible (k/nα) or high structural floor (intrinsically diffuse)? | Add clean comply prompts; commit the endpoint knot only if its floor is low, else treat as a soft anchor |
| Hyperparameter / intractability, knobs (K, PCA dim, extrapolation) multiply per layer | A cost risk, not a data diagnostic: the joint search grows combinatorially with steered layers | Staged search: tune the global surface (B) first, refine per layer only where CIs demand. Bounds, but does not guarantee, tractability |
Tractability of the per layer program is itself an open empirical question, not a settled one.
Limitations and Confidence
The strongest version of the thesis says the ceiling is geometric. Honesty requires naming the experimental choices that could instead account for it: two stand out, and both happen to be ones the rotation result itself predicts would matter.
Model scale. Both models are mid sized (7–9B). The parent method (García-Ferrero, Montero & Orus, arXiv:2512.16602) reports generalizing across 4B and 80B models, and its headline removes politically sensitive topic refusal on Qwen3-Next-80B while keeping JailbreakBench safety, so the machinery scales, and 7–9B is a tractability choice. But that 80B target (benign sensitive topic refusal, safety intact) is easier than the genuinely harmful BeaverTails compliance I test, so it does not tell me whether the ceiling section finding persists at 80B.
The broader scaling evidence is mixed, and the most refusal relevant study points against "larger = more steerable": Ali et al. (2025, arXiv:2507.11771) find that contrastive activation addition (CAA, the standard "add a single difference vector" method) diminishes in effectiveness across Llama-2 7B/13B/70B via a "drown out" mechanism: larger models' downstream computation washes out the injected vector. That is a magnitude story (the perturbation shrinks relative to the growing residual), whereas my rotation result is an alignment story (the perturbation persists, even amplifies, but lands off each layer's axis); the two are plausibly related faces of why depth defeats a single injected vector, not the same mechanism. (They also find negative steering stronger than positive, the asymmetry section result, and CAA best at early mid layers; political view steerability, by contrast, reportedly rises with scale, arXiv:2507.22623, so the picture is target dependent.) So I cannot claim the ceiling section ceiling transfers to frontier scale either way: it might lift (a larger model exposes a usable comply direction) or harden (drown out dominates). The rotation (the rotation section) should survive scale, being geometric and likely to sharpen with depth, while the ceiling (the ceiling section) and asymmetry (the asymmetry section) are the scale sensitive claims. Re measuring the ceiling at 80B is the single most valuable follow up.
Dataset breadth and category heterogeneity. The 12 BeaverTails categories are not equally steerable: per category comply rates varied widely (terrorism and sexually_explicit reached high raw rates while categories like child_abuse stayed at 0%), and several behave like near hard coded refusals. One vector, even one per category, may be a poor fit to such heterogeneous behavior, so part of the ceiling could reflect the breadth and imbalance of the category set rather than a universal geometric bound. A narrower, more homogeneous target, or per category tuning with enough data per category, might steer more readily; that the effect nonetheless replicates across two models and the cleanly composition independent rotation result both argue against this being the whole story.
Too few steered layers. I steered ~4 layers per model (the empirically best by category correlation), the sparse end of practice. Abliteration measures the refusal direction across all layers and ablates many; weighted multi layer schemes (Guiding Giants, arXiv:2505.20309) tune per layer strength across the network; single layer CAA (Rimsky et al. 2024) is the light end; and the parent method finds refusal "distributed across many dimensions" in deeper layers, which warns that a distributed signal is unlikely to be captured at four. My own rotation result predicts this underperformance: if every layer carries refusal in its own ~90° rotated frame, the ~28 unsteered layers of a 32 layer model keep processing refusal in frames the steering never touched. So the ceiling is consistent with the geometric thesis but equally with the simpler "didn't steer enough layers," not mutually exclusive (the geometry is why a few layers fail), but this experiment cannot separate them. The decisive test is to steer every layer with its own per layer vector (the dense limit of the per layer splines (above) spline) and see whether the ceiling lifts. Until then this is the largest open hole in the argument.
In sample α selection. The steering strength α was chosen by Bayesian optimization (~10 trials) and every reported steered rate is read off the same prompts that selection ran on: there is no held out split. So each rate is an in sample point estimate. Two things bound the damage. A single bounded scalar tuned over ~10 trials has little capacity to memorize 50–110 prompts (unlike fitting a high dimensional vector). The bias itself has a known direction: the comply runs optimize α to maximize compliance, so the reported comply rate is the largest a maximizer could find in sample, an upper bound. The load bearing claim is that this number is small, and in sample selection can only inflate it, never deflate it; the held out comply ceiling is the same or lower. The refusal direction rates, where objective and reported metric align, are the ones genuinely flattered. The clean fix (freeze the selected α and evaluate once on the held out BeaverTails split, the holdout exists; the steered eval was not run) is the single most useful follow up after remeasuring at scale. The rotation result is immune: it is a geometric measurement of the steering vectors, not an optimization target.
Unequal α budgets. The optimization runs do not all use the same number of trials (n ranges 7–10 α points per run). Where later Bayesian trials had stopped producing behavioural uplift, I ran fewer to save compute. That is a defensible budget choice, but it means the α surface is sampled more coarsely in some runs than others, so a sharp, narrow feature between sampled α values could be missed, and the early stop decision was itself made on the in sample objective. A uniform, denser α grid per run would close this; I have not rerun it.
Confidence by result. Net of all the above:
- Rotation (the rotation section): strong. Two families, tight CIs, two independent measurements, consistent with outside reports. Risk is on the exact ~90°/block magnitude, not the existence of rotation.
- Asymmetry (the asymmetry section): directionally solid, magnitude model dependent. The genuine compliance ceiling holds on both models, but Mistral's is higher than Qwen's and lifts on soft categories, so it is partly Qwen specific. α was selected in sample (an upper bound on compliance), and the comply class is ~72–77% benign, so this is an empirical, in sample steering outcome, not proof that a true harmful comply direction is nonfunctional.
- Hedge (the orthogonal motion section): Mistral only, most provisional. Single author hand pass (no second rater/κ), single capture layer (L29), greedy decoding, downgraded stack (transformers 4.46 / torch 2.4); the distinct basin and causal lever claims were tested and failed. Replicate first.
- Reproducibility. Backing JSONs committed and cross checked against the result docs (12/12 reproduce); hedge runs should be reconfirmed on the pinned stack.
What This Means for Steering Research
The contribution is not "steering doesn't work." It is a specific account of why single vector steering hits a ceiling, layer local rotation plus a comply direction that yields little genuine compliance at coherence preserving strength, with the measurements that establish it and the architecture that follows. The single direction picture (Arditi et al. 2024) needs amendment, not demolition: a per layer ablation can isolate a real direction while that direction rotates across layers, and the rotation is what bounds multi layer steering. Joad et al. (2026) reach a parallel conclusion from refusal categories, and Wollschläger et al. (2025) from concept cones. The practical takeaway: treat the refusal axis as layer specific and rotating, and steer along the manifold rather than adding one vector everywhere. Splines are one response; per layer vector families and learned rotation aware probes follow from the same finding.
Reproducibility
All experiments reproduce from activation steering asymmetry (Qwen3.5-9B and Mistral-7B on BeaverTails):
- Axis rotation (the rotation section):
analyze_axis_rotation.py(bootstrap CIs on consecutive layer difference vector angles). - Causal propagation (the rotation section):
analyze_causal_propagation.py(per layer alignment and norm of an injected perturbation, the tables in the rotation section). - Asymmetry / geometric privilege (the asymmetry section):
random_direction_control.py(KL versus the random direction floor), withcompute_wrmd.py,find_best_layers.py,optimize_alpha.py. - Hedge geometry (the orthogonal motion section): the
hedge_*_mistral.pyscripts (regime geometry, bootstrap CIs, bow null test, causal test). - False positive correction (the ceiling section):
fp_correction_qa.py. - Full run:
bash run_pipeline.sh.
The learning curve floor analysis in where this can fail (above) ( feature bootstrapping toolkit) is proposed tooling for the spline follow up: it was not used in the experiments above.
Notation and Terms
| Term | Meaning |
|---|---|
| α (alpha) | Steering strength: the model is steered as h' = h + α·v. "Safe / coherence preserving α" is the largest ‖α‖ before the output degenerates. |
| Difference / WRMD vector | mean(refused) − mean(complied) at a layer, that layer's refusal axis, and the steering vector itself (in the weighted, covariance adjusted WRMD form). |
norm_ratio | ‖Δh_l‖ / ‖α·v_src‖, how much of an injected perturbation's size survives at layer l (1.0 = full injected size; <1 = decayed; >1 = amplified). A magnitude, not a cosine. |
cos(Δh_l, v_l) | Alignment of the propagated perturbation with layer l's own refusal axis (Sinii et al.'s Diff Vector CosSim); falls to ~0 within one block. |
cos(Δh_l, v_src) | The perturbation's self alignment with the source vector (Sinii et al.'s Diff Diff CosSim); stays positive across depth. |
| Angular distance | Mean pairwise angle between category steering vectors, how separated the categories are. |
| Angular spread | Standard deviation of those pairwise angles, how dispersed (tight = shared subspace; wide = diverging). |
| Geometric privilege | A steering vector whose KL on neutral prompts is lower than every equal norm random direction sampled (below their minimum, tens of × below their mean), cheap to push with little distributional damage. "Percentile" here means rank within that random direction distribution, not a significance p value. |
| Orthogonal fraction | Share of the steering induced activation centroid shift that is perpendicular to the steering axis. |
Hedge / t / bow | Hedge = a response delivering content wrapped in caveats. t = position on the refuse(0)→comply(1) segment. bow = distance of a point off that segment. |
| Structural floor / volume instability | From the learning curve fit instability ≈ k/nα + floor: the floor is irreducible (more data won't fix it); the k/nα term is volume instability that shrinks as prompts are added. |
References
- Sinii et al. (2025). Small Vectors, Big Effects: A Mechanistic Study of RL Induced Reasoning via Steering Vectors. arXiv:2509.06608. Defines Diff Diff CosSim (a propagated perturbation's self alignment, which stays consistently > 0.3) versus Diff Vector CosSim (alignment with each layer's own steering vector, which falls to near zero with distance).
- Jiang, Zhou & Zhu (2024). Tracing Representation Progression: Analyzing and Enhancing Layer-Wise Similarity. arXiv:2406.14479 (ICLR 2025). Layer-wise representational similarity is positive and increases as layers get closer (so far apart layers are least similar), attributed to the residual connection.
- Wollschläger et al. (2025). The Geometry of Refusal in Large Language Models: Concept Cones and Representational Independence. arXiv:2502.17420 (ICML 2025). Refusal mediated by multiple independent directions and multi dimensional concept cones, not a single direction.
- Vu & Nguyen (2025). Angular Steering: Behavior Control via Rotation in Activation Space. arXiv:2510.26243 (NeurIPS 2025). Frames steering as rotation of activations within a 2D subspace; refusal and emotion steering use cases.
- Arditi et al. (2024). Refusal in Language Models Is Mediated by a Single Direction. arXiv:2406.11717 (NeurIPS 2024). A one dimensional, per layer refusal direction across 13 models up to 72B; implicitly assumes cross layer stability.
- Joad et al. (2026). There Is More to Refusal in Large Language Models than a Single Direction. arXiv:2602.02132. Across eleven refusal/noncompliance categories, refusal corresponds to geometrically distinct directions, affecting how the model refuses, not whether.
- Zou et al. (2023). Representation Engineering: A Top-Down Approach to AI Transparency. arXiv:2310.01405. Reads control/concept directions per layer; a qualitative precursor to the quantified cross layer rotation.
- García-Ferrero, Montero & Orus (2025). Refusal Steering: Fine-grained Control over LLM Refusal Behaviour for Sensitive Topics. arXiv:2512.16602. The method this work extends: ridge regularized WRMD steering vectors with LLM as judge confidence weighting; reports generalizing across 4B and 80B models on politically sensitive topics, with the headline result on Qwen3-Next-80B-A3B-Thinking, and refusal signals found concentrated in deeper layers but distributed across many dimensions.
- Ali, Xu, Yang, Li, Arslan & Benham (2025). Scaling Laws for Activation Steering with Llama 2 Models and Refusal Mechanisms. arXiv:2507.11771. CAA effectiveness diminishes with model size (7B/13B/70B); "drown out" hypothesis; negative steering more pronounced than positive; CAA most effective at early mid layers. The refusal specific scaling counterpoint to "larger = more steerable."
- Multilingual Political Views of Large Language Models: Identification and Steering (2025). arXiv:2507.22623 (ACL/IJCNLP Findings 2025). Scale dependent baseline ideological lean across LLaMA-3.1 / Qwen-3 / Aya-Expanse; center of-mass steering of attention head outputs across multiple layers.
- Guiding Giants: Lightweight Controllers for Weighted Activation Steering in LLMs (2025). arXiv:2505.20309. Weighted multi layer steering with per layer strength control.
- Rimsky et al. (2024). Steering Llama 2 via Contrastive Activation Addition. arXiv:2312.06681. CAA; the few layer / single layer end of steering practice.
Discussion and Replication
Feedback, replication attempts, and pointers to related work are welcome, especially on the open question of whether the ceiling persists at frontier scale. The full experimental code and backing data are linked below; the rotation and asymmetry results reproduce end to end, and the hedge geometry should be reconfirmed on the pinned stack before it is relied on.
Full replication scripts and backing data are available at github.com/ElSnacko/activation-steering-asymmetry.
← Back to home